
Rebuilding Master Node
This article will show us how to recover from a lost master node. This assumes a UPI-based install but this process should work the same with even IPI methods. The advantage you will have with a IPI-based install, is through the use of MachineSets but that won’t be mentioned here (yet).
For demonstration purposes, let’s assume that hub-rm5rq-master-0 crashed and needs to be rebuilt. I deleted the VM to simulate a failure. Replacing a master is based on steps from https://docs.openshift.com/container-platform/4.7/backup_and_restore/replacing-unhealthy-etcd-member.html#restore-replace-stopped-etcd-member_replacing-unhealthy-etcd-member
Backup ETCD State
OCP comes with scripts that will backup the etcd state. Eventhough hub-rm5rq-master-0 is already unavailable, it is nice to have a backup just in case any additional problems arise (IE: human error) and the cluster ends up in a worst-state.
- Determine which master node is currently the leader. To do this, change to the openshift-etcd project.
oc project openshift-etcd
List the etcd pods in this project.
oc get po
2. RSH into any of the etcd pods.
oc rsh etcd-hub-rm5rq-master-1
3. From within that pod, run the following command to see the etcd cluster leader:
etcdctl endpoint status -w table
You will also notice that only 2 etcd members exist. This is because the etcd pod associated with hub-rm5rq-master-0 no longer exists.
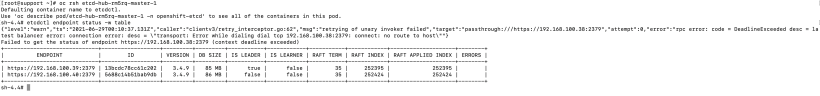
4. Take note of the etcd pod that is the current leader. This is where the backup script will be run from.
The IP of the leader is 192.168.100.39.
Running the following command will show the master that this pod is running on.
oc get po -o wide
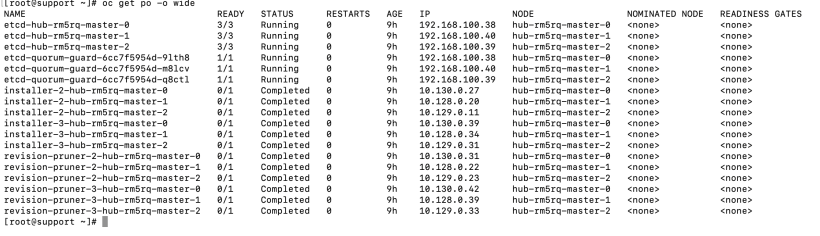
5. Let’s run the following command to go to the node that is running the leader etcd pod. The IP is 192.168.100.39 and this corresponds to the master node called hub-rm5rq-master-2.
oc debug node/hub-rm5rq-master-2
6. To get to the host operating system, run:
chroot /host
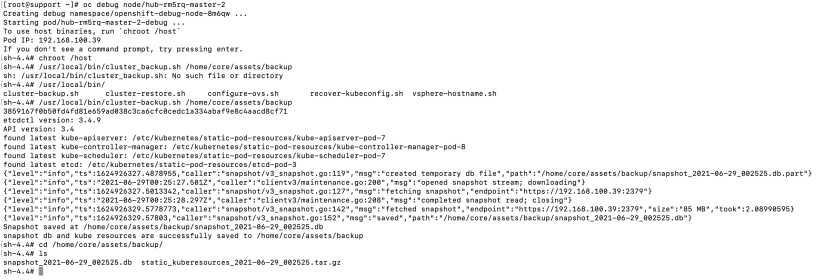
7. Now, run the backup script.
/usr/local/bin/cluster_backup.sh /home/core/assets/backup
8. Verify that the backup exists in /home/core/assets/backup. A snapshot db file and kuberesource.tar.gz file should exist. Move these files somewhere else (just in case).
Clean-Up process
First, we need to remove the old node so it no longer appears in the output of “oc get nodes”. We also need to remove any old secrets, and remove the etcd member from the etcd database.
- Run the following command to remove the failed node from OCP:
oc delete node hub-rm5rq-master-0
2. Confirm the deletion by running:
oc get nodes
3. Within the openshift-etcd project, connect to one of the remaining etcd pods. Earlier, we used etcd-hub-rm5rq-master-1
oc project openshift-etcd
oc rsh etcd-hub-rm5rq-master-1
4. List the etcd members:
etcdctl member list -w table
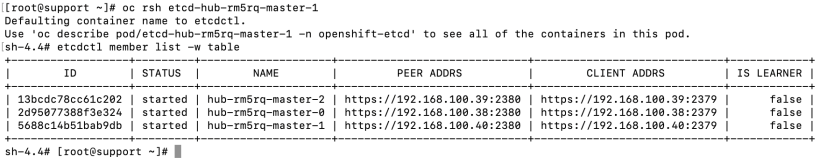
5. Take note of the ID associated with the failed master. In my case, the failed master is hub-rm5rq-master-0 and its ID is 2d95077388f3e324.
6. Delete this ID from the etcd database.
etcdctl member remove 2d95077388f3e324

6. Verify that the member is removed:
etcdctl member list -w table
The failing etcd member should no longer appear on the list.

7. Now, let’s find the secrets that are associated with the failed etcd member. There is a secret for peer, serving, and serving-metrics secret.
oc get secrets|grep hub-rm5rq-master-0
8. Remove each of these secrets
oc delete secret etcd-peer-hub-rm5rq-master-0
oc delete secret etcd-serving-hub-rm5rq-master-0
oc delete secret etcd-serving-metrics-hub-rm5rq-master-0

Rebuilding hub-rm5rq-master-0
- To get the contents of the CA cert, run the following OC command:
oc describe cm root-ca -n kube-system
You will want to grab the cert and save to a file (such as ca.crt).
2. Take the contents of the certificate and encode into base64 format.
cat ca.crt|base64 -w0 > ca.crt.base64
3. To build the ignition file needed to restore/replace this worker, we will use the following template:
{“ignition”:{“config”:{“merge”:[{“source”:”https://<apifqdn>:22623/config/master”}]},”security”:{“tls”:{“certificateAuthorities”:[{“source”:”data:text/plain;charset=utf-8;base64,<base64decodedcrt>”}]}},”version”:”3.1.0″}}
Replace the <apifqdn> with the fqdn of your api server.
Replace the <base64decodedcacrt with the contents of ca.crt.base64decodedcacrt
Place this file on a web server that is reachable from the control-plane network.
A sample of this file is located at:
https://github.com/kcalliga/adding_master_node/blob/main/master.ign.sample
4. Download the ISO based on version of OCP that you are running (this cluster is 4.7.13). The ISO images are located at:
https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/latest/
My specific ISO is https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/latest/4.7.13/rhcos-4.7.13-x86_64-live.x86_64.iso
5. In my case, I am using a virtual machine but you can also boot your physical machine from this ISO.
6. When the ISO is booted, run the following command:
sudo coreos-installer install \
–ignition-url=https://host/master..ign /dev/sda
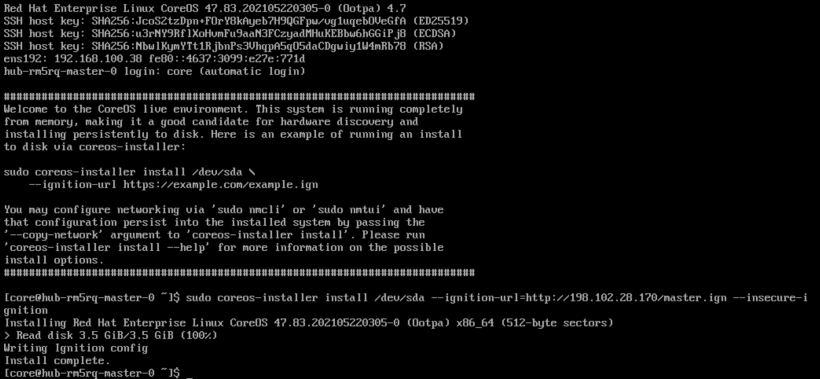
7. Once the install is complete, you can issue a reboot command. Sometimes the node will not reboot automatically.
8. The node will reboot a few times to apply the various machine configs.
9. Lastly, wait for some new CSR requests to come in based on the new worker node by issuing the following command:
oc get csr
10. You can loop through each of the requests that come in by issuing the following command:
for i in ``oc get csr|awk '{print $1}'|grep -v NAME`; do oc adm certificate approve $i; done;You may need to issue this command a few times based on some new/pending requests coming in.

11. After approving the CSRs, issue the “oc get node” command. This command will show the new master registered to the cluster. It may show a “Not Ready” status momentarily but will evenutally go to a “Ready” status. The node we are looking for is hub-rm5rq-master-0.

Verification
Now that the hub-rm5rq-master-0 node has been rebuilt, we need to ensure that the pods are running and force a redeployment of this etcd member using the etcd operator.
1. Make sure all etcd pods have been recreated (including the new one).
oc get pods -n openshift-etcd| grep -v etcd-quorum-guard|grep etcd

2. Force redeployment of etcd cluster.
oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
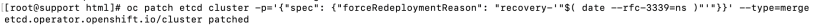
3. Check to ensure that new etcd member is online. You can RSH into any of the etcd pods.
oc rsh etcd-hub-rm5rq-master-1
etcdctl member list -w table
etcdctl endpoint status -w table
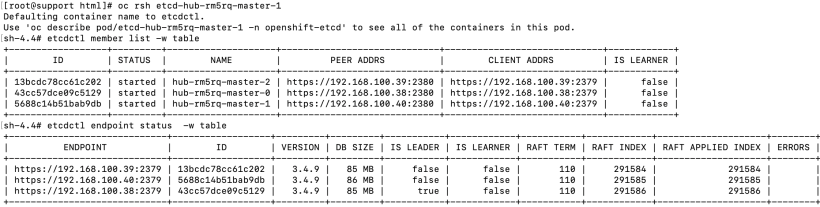
All 3 etcd members are online. I hope you have found this article helpful.