
Fully Self-Contained OCP Cluster
Some customers are looking at ways of deploying OCP clusters in a manner in which the cluster is totally self-sufficient meaning that once the cluster is built, there is no reliance on an any resources outside the cluster (not even a registry). Think of an edge deployment or an isolated environment that has no connection to the outside world (IE: disconnected environment).
The resources that are typically required by any running cluster are a DHCP server, DNS server, external registry, etc.
We are looking at this type of deployment for the smaller-footprint (one less server) to fit into a small space (IE: closet). 6 small-form factor servers can be used for this deployment (3 masters and 3 workers).
Here are some requirements that were given to us based on this deployment:
-No Virtualization (bare-metal)
-Small form-factor servers
-No upstream DNS server
-No DHCP Server (static IP addressing can occur in the Assisted Installer GUI)
-No External or Mirrored Registry (after install/moving to isolated environment)
The idea with this experiment is to create the OCP clusters in an assembly-line fashion. IP addresses, FQDN, cluster names can be the exact same for each cluster that is deployed. A registry will be used at the staging site to build the cluster but there will be no registry once the cluster is moved.
When the OCP clusters are built in an assembly-line function, it was found that an action that needed to be performed to ensure the cluster came up properly once it reached its destination. This was to find a way to store every image that is used on the cluster locally on each node since there is no registry or any upstream DNS servers at the deployment site.
One of the impacts of having a standalone OCP cluster without any DNS servers (and before caching images) is that some of the nodes would not come up all the way if the nodes were rebooted. The symptoms of a node or cluster being rebooted without any DNS or external connectivity (disconnected environment), is as follows:
- Since there is a Systemd process on the nodes that occasionally wipes old images (mostly after unclean shutdowns), the nodes would not have the images needed to even be able to start the Kubelet process (openshift-release images)
- In other cases, even when Kubelet starts, there may be other images that will fail to pull (ImagePullBackoff) due to no DNS resolution or outside connectivity. Typically, at a minimum, quay.io and registry.redhat.io need to resolve and be reachable on a normal/connected cluster.
- Furthermore, the lack of external connectivity and no physical space for an internal registry requires additional space on each node to be used to cache OCP base (and Operator) images.
This article will cover the steps I followed to test the behavior of a cluster that boots up without a DNS server and without a connection to the Internet (or any registry).
These steps don't account for cluster lifecycle (like upgrades). This is assuming we deploy the cluster and leave alone (for the time being). Upgrades would be another process and article.
This also assumes that workloads in the cluster only connect among themselves and there is no reliance on anything outside the cluster.
For accessing the web console or any other web front-ends such as ACM, /etc/hosts entries (typically oauth route/web console/multiclusterhub) would need to be added to computer/laptop once it is connected to this isolated cluster's network.
Building Cluster
This writing involves building a bare-metal OCP cluster. I am using the latest 4.9 build (4.9.43). It was built using Assisted Installer. My environment has 3 combination master/worker nodes. I am running these VMs using Libvirtd/KVM. At build-time, these nodes are connected to the Internet through a NAT (virtual bridge). They are in the 192.168.100.X network.
At build-time, there is Internet connectivity and DNS is configured based on our official documentation. This involves creating A records for each node, api, ingress, etc.
I had to increase the size of the drive (operating system drive) on my OCP nodes to account for additional images. If you are just concerned with OCP release images, this won't be much but it could be a lot more depending on whether you want to have all operator content (300+GB).
Another important note is to use VirtIO storage drivers if using Libvirtd/KVM for virtualization. The other drivers will be slow when doing some of our copy commands later.
Installing some Additional Images on Cluster Needed for an Operator
Once the cluster is built, I will install some add-on operators just to show how you how to use the catalog (and oc get commands) to find the list of images required by each operator.
Due to limitations in my lab environment, I can't install ODF (Openshift Data Foundations) for storage but will install another Operator. Advanced Cluster Management (ACM) will be used. This is a good one because there are a lots of sub-components (images) for this that we will need to account for when we do our caching. Most operators will work in the same manner.
Here are the exact steps I followed to install ACM. These steps occur right after the cluster is built.
- Open up the Openshift Web Console.
- On the left-side, go to Operators --> OperatorHub
- Search for "Advanced Cluster Management"
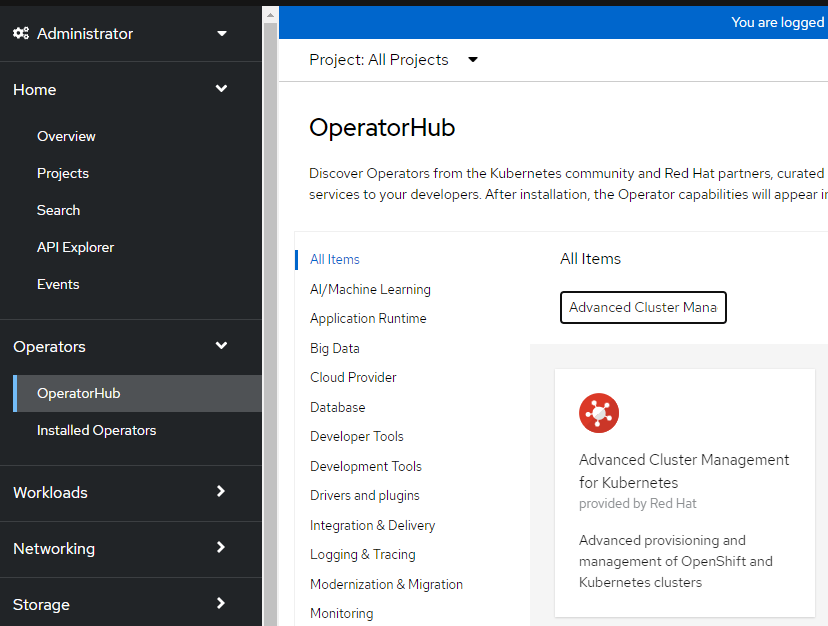
4. Install this Operator using all default settings.
5. Once ACM Operator is installed, let's create the MultiClusterHub. Use all the default options at this point.
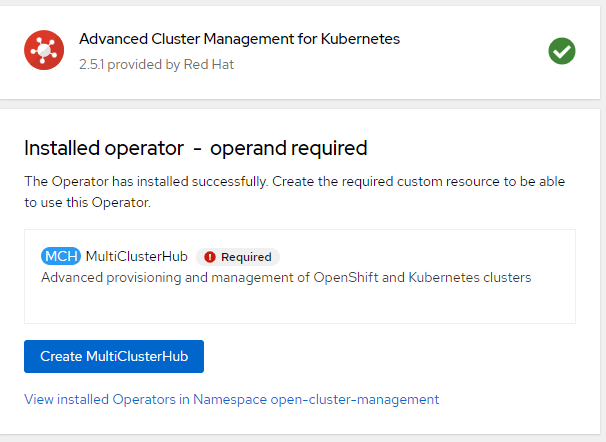
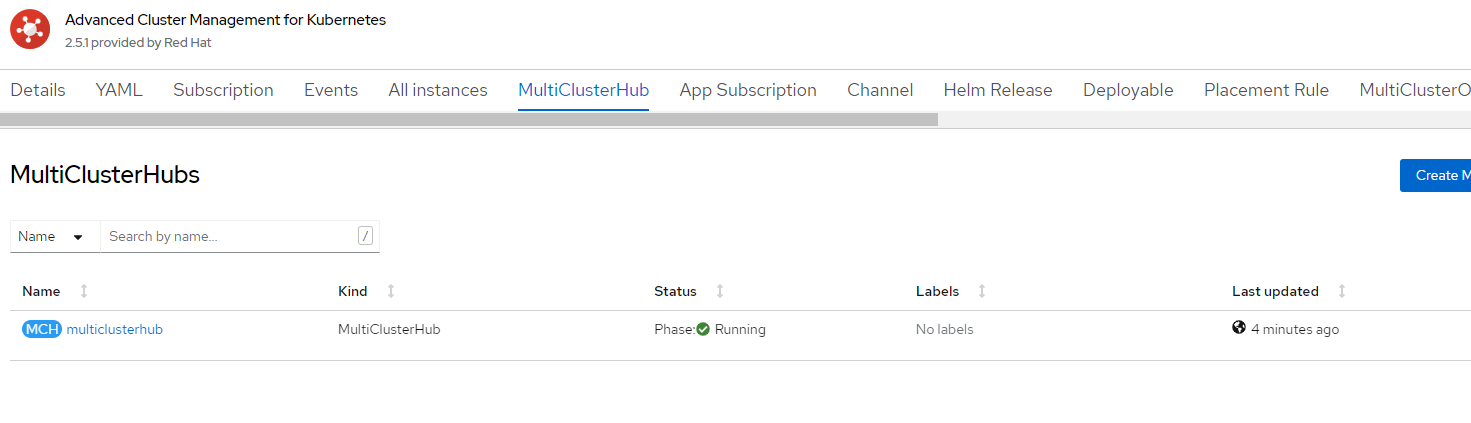
6. Wait for MultiClusterHub to be in an installed state.
Creating a Virtualized Isolated Environment
These steps have been updated a few times. I originally created an isolated network inside of Libvirt without a gateway but found that this did not work due to requirements of 172.30 cluster network needing a gateway/route out.
The easiest method to have a disconnected cluster in my environment is by removing the entries in /etc/resolv.conf on the hypervisor and ensuring that the OCP nodes can't resolve any addresses outside of the cluster.
Looking at Behavior of Connected and Isolated Cluster
For this part, I want to see what the normal behavior is like when doing a reboot on all of the nodes. This will require tcpdump and Wireshark. Find the bridge associated with the live network that your cluster (bridge is called internal in Virt-Manager) is currently on. In my case, this is virbr1.
We will want to look at traffic on this bridge that is destined for outside (not in 192.168.100.0/24 internal network).
- In one window on your hypervisor host, run the following:
tcpdump -i virbr1 dst net not 192.168.100.0/24I ran this command before I rebooted the nodes just to be sure I am getting some output. See the NTP traffic going out below. In my environment, NTP is going out to the Internet. You'll want some type of NTP internal on your routers/switches, etc.

2. Now, reboot your OCP nodes.
shutdown -r nowSee all of the output
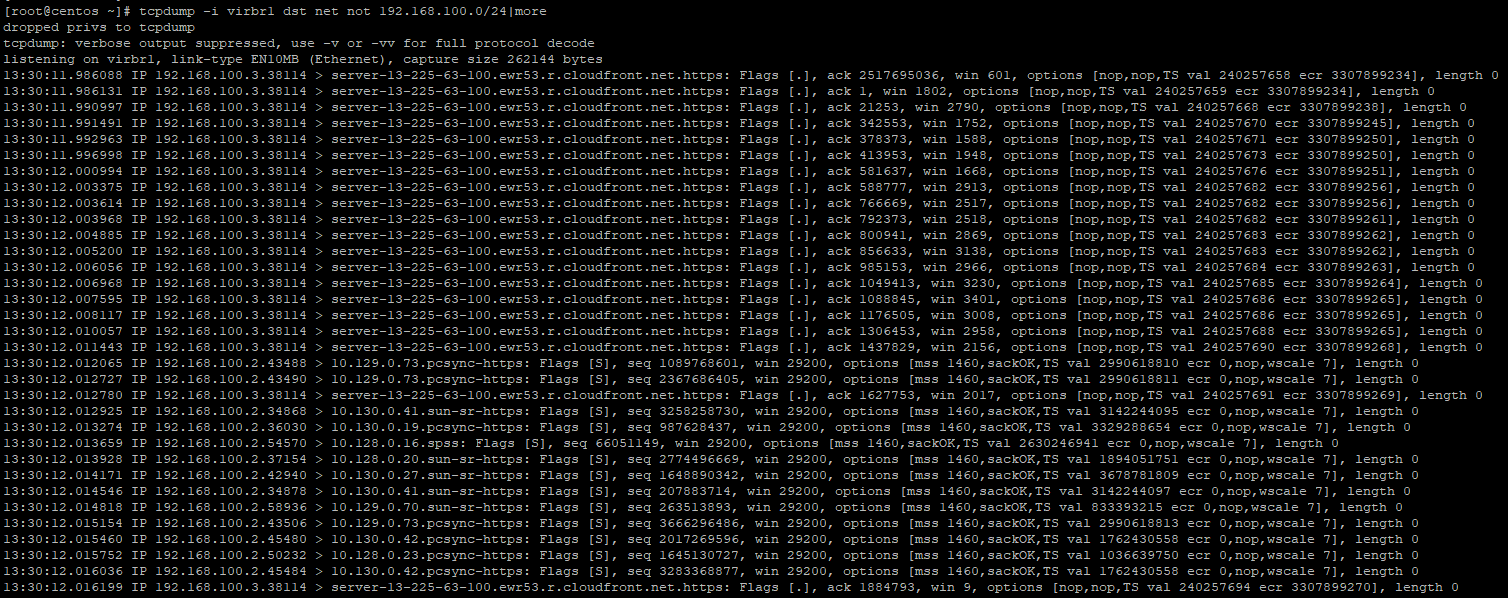
This is all web traffic and most likely being used to pull down images from either registry.redhat.io, quay.io, or associated CDN network.
3. Let's now see what the behavior is if we switch the OCP nodes to be isolated. As you recall, this will involve removing the entries in /etc/resolv.conf from the hypervisor node.
4. Let's reboot the nodes using virt-manager GUI. Debug pod might not work due to being unable to download that container.
5. Run the following command to see if any pods have failed:
oc get po -A|grep -ve Running -ve Completed
You should see at least the marketplace pods failing and maybe some others.
The reason most of the pods startup is because we did not do an eviction and we also did a clean shutdown.
Let's see the behavior when the power is essentially pulled.
8. In Virt-Manager, power off the OCP nodes without shutting them down (force off).
9. Power the nodes back on.
10. You will probably see some odd behavior.
SSH may not work to the nodes
You can't run any oc commands against the nodes
This is most likely due to a combination of things.
-There is no DNS server for the nodes to contact the machine config operator
-All images were wiped due to unclean shutdown (crio-wipe service)
We will fix these issues in a bit.
11. Let's now connect the nodes back to the regular network and reboot the nodes one more time.
12. We will now need to run our oc commands back from our regular hypervisor node. It may take a little longer for cluster to come back up because all of the nodes need to redownload ocp-release and operator images.
Let's ensure we can run a few simple commands against the cluster
oc get nodes
# There should be no output to the next command except for headers
oc get po -A|grep -ve Running -ve CompletedNow, we will go onto the next steps of preparing the environment to be isolated.
Caching of Images
As I mentioned, one way to get around this would be to configure an additional location for the CRIO Imagestore on each master/worker. At a minimum, this imagestore would need to have the openshift-release images and anything else that is critical for key services in the cluster to start. ACM is installed for this cluster so we would need to have ACM images available.
The advantage to this alternate location for the images is that this data will never be wiped as a result of the crio-wipe service that is configured on each node when a node is forcibly shutdown. We could technically disable this service but having this alternate location is an additional fail-safe mechanism (in my opinion).
We need to have all of the images that are needed on every node (because the workloads will not always get scheduled to the same nodes they are already on).
Here are the exact steps we can follow:
- To gather the list of images that are needed for the cluster, find the specific OCP release that you are building. In this example, I am using 4.9.43
https://mirror.openshift.com/pub/openshift-v4/clients/ocp/4.9.43/release.txt
In this release.txt file, there are 141 images/digests.
To get the list of images, do the following:
cat release.txt |grep openshift-release-dev|grep quay.io|awk '{print $2}'|grep -v From > images.lstIn this release.txt is list of the 141 images/digests that make up the OCP install.
For specific operators, there are a few additional steps you will need to perform in order to get this full list. Change opererator-index to match major release of OCP.
oc adm catalog mirror registry.redhat.io/redhat/redhat-operator-index:v4.9 file:///local/index -a pull-secret.json --insecure --index-filter-by-os='linux/amd64' --manifests-onlyThe output will look similar to the following:
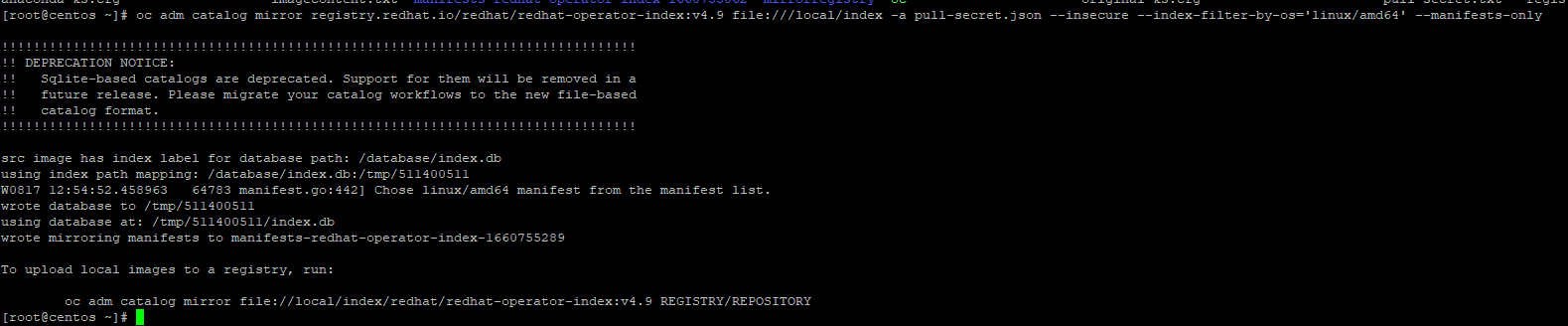
A directory called manifests-redhat-operator-index-1660755289 was created in this example.
If I CD to this directory, I can run the following command to get list of images by operator.
#Shows lists of operators
cat mapping.txt |awk -F "/" '{print $2}'|sort|uniq
# Let's pick rhacm2 to see the whole list of rhacm images and append to our #images.lst file
grep rhacm2 mapping.txt >> images.lst
# Do the same for any other operatorIt is highly recommended to double-check the list of directories/operators. In some cases, there may be a tech-preview directory that is separate from the main operator. For ACM, you may want list of images from rhacm2 and rhacm2-tech-preview.
The key is to install all operators that you need before moving the cluster to isolated network. Forcibly shutdown the node multiple times to ensure every image that you need is available.
When cluster comes up, keep running the following command to make sure there are no ImagePullBackoff errors.
oc get po -A|grep -ve Running -ve Completed
If there are any ImagePullBackOff errors, find the image name and add it to your images.lst file and repeat.
Another way to see list of images on current setup is run the following commands (this was the old way I gathered list of images in my previous revision of article). This will have some of the images in the list that we already gathered. I don't recommend this step anymore because you may miss something. It is here only for reference.
# Get list of images for all pods running currently in cluster
oc get po -A|awk '{print "oc describe po "$2" -n " $1}' > workloads.sh
# Get list of CronJobs that run in cluster and associated images
oc get cronjob -A|awk '{print "oc describe po "$2" -n " $1}' >> workloads.sh;
./workloads.sh|grep "Image:"|sort|uniq|awk '{print $2}' >> images.lst;
2. This images.lst file should look as follows. The output shown here is abbreviated.
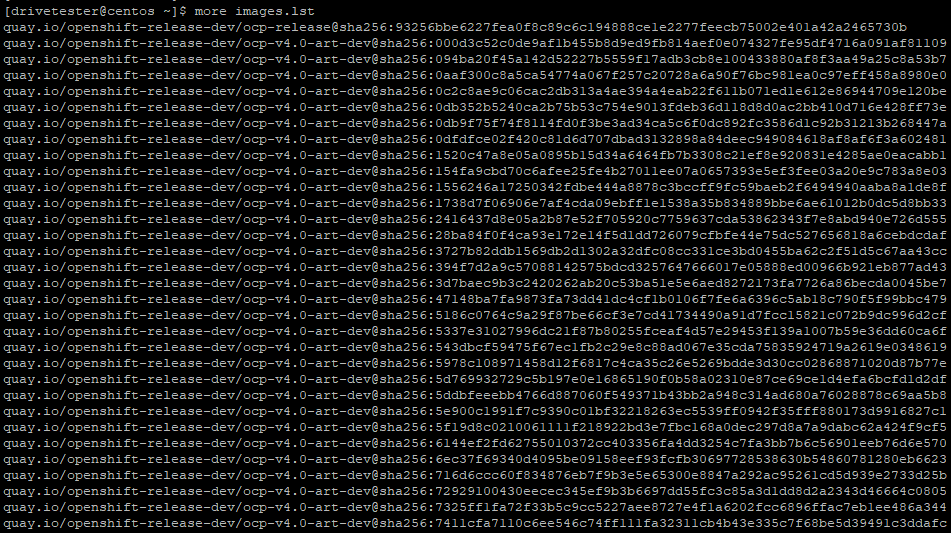
Here is the bottom of list showing catalog images and ACM images
Copy images.lst file to each OCP node.
3. On each node, run the following (crictl needs to be used to pull digests)
# ssh as core user
sudo -;
cd /home/core;
for image in `cat images.lst`; do crictl pull $image; done;In some cases, the images will already exist. A message saying that "image is up to date" may be displayed.
4. Let's create an alternate location to store some local images
Run this set of commands on each node (as root).
mkdir /home/core/images;
cd /var/lib/containers/storage;
cp -ar * /home/core/images 2> /dev/null;
5. Let's first pause the MCP pool for the group of servers we are working on. In my case, this is the master pool.
Add Machine Config to use additional ImageStore location.
99-container-storage-conf machine-config-master (just change label to apply this to workers)
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 99-container-master-storage-conf
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: >-
data:text/plain;charset=utf-8;base64,IyBUaGlzIGZpbGUgaXMgZ2VuZXJhdGVkIGJ5IHRoZSBNYWNoaW5lIENvbmZpZyBPcGVyYXRvcidzIGNvbnRhaW5lcnJ1bnRpbWVjb25maWcgY29udHJvbGxlci4KIwojIHN0b3JhZ2UuY29uZiBpcyB0aGUgY29uZmlndXJhdGlvbiBmaWxlIGZvciBhbGwgdG9vbHMKIyB0aGF0IHNoYXJlIHRoZSBjb250YWluZXJzL3N0b3JhZ2UgbGlicmFyaWVzCiMgU2VlIG1hbiA1IGNvbnRhaW5lcnMtc3RvcmFnZS5jb25mIGZvciBtb3JlIGluZm9ybWF0aW9uCiMgVGhlICJjb250YWluZXIgc3RvcmFnZSIgdGFibGUgY29udGFpbnMgYWxsIG9mIHRoZSBzZXJ2ZXIgb3B0aW9ucy4KW3N0b3JhZ2VdCgojIERlZmF1bHQgU3RvcmFnZSBEcml2ZXIKZHJpdmVyID0gIm92ZXJsYXkiCgojIFRlbXBvcmFyeSBzdG9yYWdlIGxvY2F0aW9uCnJ1bnJvb3QgPSAiL3Zhci9ydW4vY29udGFpbmVycy9zdG9yYWdlIgoKIyBQcmltYXJ5IFJlYWQvV3JpdGUgbG9jYXRpb24gb2YgY29udGFpbmVyIHN0b3JhZ2UKZ3JhcGhyb290ID0gIi92YXIvbGliL2NvbnRhaW5lcnMvc3RvcmFnZSIKCltzdG9yYWdlLm9wdGlvbnNdCiMgU3RvcmFnZSBvcHRpb25zIHRvIGJlIHBhc3NlZCB0byB1bmRlcmx5aW5nIHN0b3JhZ2UgZHJpdmVycwoKIyBBZGRpdGlvbmFsSW1hZ2VTdG9yZXMgaXMgdXNlZCB0byBwYXNzIHBhdGhzIHRvIGFkZGl0aW9uYWwgUmVhZC9Pbmx5IGltYWdlIHN0b3JlcwojIE11c3QgYmUgY29tbWEgc2VwYXJhdGVkIGxpc3QuCmFkZGl0aW9uYWxpbWFnZXN0b3JlcyA9IFsiL2hvbWUvY29yZS9pbWFnZXMiLF0KCiMgU2l6ZSBpcyB1c2VkIHRvIHNldCBhIG1heGltdW0gc2l6ZSBvZiB0aGUgY29udGFpbmVyIGltYWdlLiAgT25seSBzdXBwb3J0ZWQgYnkKIyBjZXJ0YWluIGNvbnRhaW5lciBzdG9yYWdlIGRyaXZlcnMuCnNpemUgPSAiIgoKIyBSZW1hcC1VSURzL0dJRHMgaXMgdGhlIG1hcHBpbmcgZnJvbSBVSURzL0dJRHMgYXMgdGhleSBzaG91bGQgYXBwZWFyIGluc2lkZSBvZgojIGEgY29udGFpbmVyLCB0byBVSURzL0dJRHMgYXMgdGhleSBzaG91bGQgYXBwZWFyIG91dHNpZGUgb2YgdGhlIGNvbnRhaW5lciwgYW5kCiMgdGhlIGxlbmd0aCBvZiB0aGUgcmFuZ2Ugb2YgVUlEcy9HSURzLiAgQWRkaXRpb25hbCBtYXBwZWQgc2V0cyBjYW4gYmUgbGlzdGVkCiMgYW5kIHdpbGwgYmUgaGVlZGVkIGJ5IGxpYnJhcmllcywgYnV0IHRoZXJlIGFyZSBsaW1pdHMgdG8gdGhlIG51bWJlciBvZgojIG1hcHBpbmdzIHdoaWNoIHRoZSBrZXJuZWwgd2lsbCBhbGxvdyB3aGVuIHlvdSBsYXRlciBhdHRlbXB0IHRvIHJ1biBhCiMgY29udGFpbmVyLgojCiMgcmVtYXAtdWlkcyA9IDA6MTY2ODQ0MjQ3OTo2NTUzNgojIHJlbWFwLWdpZHMgPSAwOjE2Njg0NDI0Nzk6NjU1MzYKCiMgUmVtYXAtVXNlci9Hcm91cCBpcyBhIG5hbWUgd2hpY2ggY2FuIGJlIHVzZWQgdG8gbG9vayB1cCBvbmUgb3IgbW9yZSBVSUQvR0lECiMgcmFuZ2VzIGluIHRoZSAvZXRjL3N1YnVpZCBvciAvZXRjL3N1YmdpZCBmaWxlLiAgTWFwcGluZ3MgYXJlIHNldCB1cCBzdGFydGluZwojIHdpdGggYW4gaW4tY29udGFpbmVyIElEIG9mIDAgYW5kIHRoZSBhIGhvc3QtbGV2ZWwgSUQgdGFrZW4gZnJvbSB0aGUgbG93ZXN0CiMgcmFuZ2UgdGhhdCBtYXRjaGVzIHRoZSBzcGVjaWZpZWQgbmFtZSwgYW5kIHVzaW5nIHRoZSBsZW5ndGggb2YgdGhhdCByYW5nZS4KIyBBZGRpdGlvbmFsIHJhbmdlcyBhcmUgdGhlbiBhc3NpZ25lZCwgdXNpbmcgdGhlIHJhbmdlcyB3aGljaCBzcGVjaWZ5IHRoZQojIGxvd2VzdCBob3N0LWxldmVsIElEcyBmaXJzdCwgdG8gdGhlIGxvd2VzdCBub3QteWV0LW1hcHBlZCBjb250YWluZXItbGV2ZWwgSUQsCiMgdW50aWwgYWxsIG9mIHRoZSBlbnRyaWVzIGhhdmUgYmVlbiB1c2VkIGZvciBtYXBzLgojCiMgcmVtYXAtdXNlciA9ICJzdG9yYWdlIgojIHJlbWFwLWdyb3VwID0gInN0b3JhZ2UiCgpbc3RvcmFnZS5vcHRpb25zLnRoaW5wb29sXQojIFN0b3JhZ2UgT3B0aW9ucyBmb3IgdGhpbnBvb2wKCiMgYXV0b2V4dGVuZF9wZXJjZW50IGRldGVybWluZXMgdGhlIGFtb3VudCBieSB3aGljaCBwb29sIG5lZWRzIHRvIGJlCiMgZ3Jvd24uIFRoaXMgaXMgc3BlY2lmaWVkIGluIHRlcm1zIG9mICUgb2YgcG9vbCBzaXplLiBTbyBhIHZhbHVlIG9mIDIwIG1lYW5zCiMgdGhhdCB3aGVuIHRocmVzaG9sZCBpcyBoaXQsIHBvb2wgd2lsbCBiZSBncm93biBieSAyMCUgb2YgZXhpc3RpbmcKIyBwb29sIHNpemUuCiMgYXV0b2V4dGVuZF9wZXJjZW50ID0gIjIwIgoKIyBhdXRvZXh0ZW5kX3RocmVzaG9sZCBkZXRlcm1pbmVzIHRoZSBwb29sIGV4dGVuc2lvbiB0aHJlc2hvbGQgaW4gdGVybXMKIyBvZiBwZXJjZW50YWdlIG9mIHBvb2wgc2l6ZS4gRm9yIGV4YW1wbGUsIGlmIHRocmVzaG9sZCBpcyA2MCwgdGhhdCBtZWFucyB3aGVuCiMgcG9vbCBpcyA2MCUgZnVsbCwgdGhyZXNob2xkIGhhcyBiZWVuIGhpdC4KIyBhdXRvZXh0ZW5kX3RocmVzaG9sZCA9ICI4MCIKCiMgYmFzZXNpemUgc3BlY2lmaWVzIHRoZSBzaXplIHRvIHVzZSB3aGVuIGNyZWF0aW5nIHRoZSBiYXNlIGRldmljZSwgd2hpY2gKIyBsaW1pdHMgdGhlIHNpemUgb2YgaW1hZ2VzIGFuZCBjb250YWluZXJzLgojIGJhc2VzaXplID0gIjEwRyIKCiMgYmxvY2tzaXplIHNwZWNpZmllcyBhIGN1c3RvbSBibG9ja3NpemUgdG8gdXNlIGZvciB0aGUgdGhpbiBwb29sLgojIGJsb2Nrc2l6ZT0iNjRrIgoKIyBkaXJlY3Rsdm1fZGV2aWNlIHNwZWNpZmllcyBhIGN1c3RvbSBibG9jayBzdG9yYWdlIGRldmljZSB0byB1c2UgZm9yIHRoZQojIHRoaW4gcG9vbC4gUmVxdWlyZWQgaWYgeW91IHNldHVwIGRldmljZW1hcHBlcgojIGRpcmVjdGx2bV9kZXZpY2UgPSAiIgoKIyBkaXJlY3Rsdm1fZGV2aWNlX2ZvcmNlIHdpcGVzIGRldmljZSBldmVuIGlmIGRldmljZSBhbHJlYWR5IGhhcyBhIGZpbGVzeXN0ZW0KIyBkaXJlY3Rsdm1fZGV2aWNlX2ZvcmNlID0gIlRydWUiCgojIGZzIHNwZWNpZmllcyB0aGUgZmlsZXN5c3RlbSB0eXBlIHRvIHVzZSBmb3IgdGhlIGJhc2UgZGV2aWNlLgojIGZzPSJ4ZnMiCgojIGxvZ19sZXZlbCBzZXRzIHRoZSBsb2cgbGV2ZWwgb2YgZGV2aWNlbWFwcGVyLgojIDA6IExvZ0xldmVsU3VwcHJlc3MgMCAoRGVmYXVsdCkKIyAyOiBMb2dMZXZlbEZhdGFsCiMgMzogTG9nTGV2ZWxFcnIKIyA0OiBMb2dMZXZlbFdhcm4KIyA1OiBMb2dMZXZlbE5vdGljZQojIDY6IExvZ0xldmVsSW5mbwojIDc6IExvZ0xldmVsRGVidWcKIyBsb2dfbGV2ZWwgPSAiNyIKCiMgbWluX2ZyZWVfc3BhY2Ugc3BlY2lmaWVzIHRoZSBtaW4gZnJlZSBzcGFjZSBwZXJjZW50IGluIGEgdGhpbiBwb29sIHJlcXVpcmUgZm9yCiMgbmV3IGRldmljZSBjcmVhdGlvbiB0byBzdWNjZWVkLiBWYWxpZCB2YWx1ZXMgYXJlIGZyb20gMCUgLSA5OSUuCiMgVmFsdWUgMCUgZGlzYWJsZXMKIyBtaW5fZnJlZV9zcGFjZSA9ICIxMCUiCgojIG1rZnNhcmcgc3BlY2lmaWVzIGV4dHJhIG1rZnMgYXJndW1lbnRzIHRvIGJlIHVzZWQgd2hlbiBjcmVhdGluZyB0aGUgYmFzZQojIGRldmljZS4KIyBta2ZzYXJnID0gIiIKCiMgbW91bnRvcHQgc3BlY2lmaWVzIGV4dHJhIG1vdW50IG9wdGlvbnMgdXNlZCB3aGVuIG1vdW50aW5nIHRoZSB0aGluIGRldmljZXMuCiMgbW91bnRvcHQgPSAiIgoKIyB1c2VfZGVmZXJyZWRfcmVtb3ZhbCBNYXJraW5nIGRldmljZSBmb3IgZGVmZXJyZWQgcmVtb3ZhbAojIHVzZV9kZWZlcnJlZF9yZW1vdmFsID0gIlRydWUiCgojIHVzZV9kZWZlcnJlZF9kZWxldGlvbiBNYXJraW5nIGRldmljZSBmb3IgZGVmZXJyZWQgZGVsZXRpb24KIyB1c2VfZGVmZXJyZWRfZGVsZXRpb24gPSAiVHJ1ZSIKCiMgeGZzX25vc3BhY2VfbWF4X3JldHJpZXMgc3BlY2lmaWVzIHRoZSBtYXhpbXVtIG51bWJlciBvZiByZXRyaWVzIFhGUyBzaG91bGQKIyBhdHRlbXB0IHRvIGNvbXBsZXRlIElPIHdoZW4gRU5PU1BDIChubyBzcGFjZSkgZXJyb3IgaXMgcmV0dXJuZWQgYnkKIyB1bmRlcmx5aW5nIHN0b3JhZ2UgZGV2aWNlLgojIHhmc19ub3NwYWNlX21heF9yZXRyaWVzID0gIjAiCg==
mode: 420
overwrite: true
path: /etc/containers/storage.conf6. This will cause all of the nodes to reboot. You will also see the machine-config-pool updating. In my case, this is master pool because I have a combination master/worker nodes.
oc get mcp
Nodes will be marked un-schedulable and reboot in succession.
Wait for all nodes to reboot.|
When all nodes are finished they will show updated: true and updating: false

The change that is specifically being made in /etc/containers/storage.conf is as follows:
additionalimagestores = ["/home/core/images",]Now Kubelet will start even when there is no DNS access (IE: when host can't connect to quay.io or registry.redhat.io to pull images).
Final Test
Let's do the same test we did earlier which is forcibly shutting down the OCP nodes and commenting out all entries in /etc/resolv.conf on hypervisor.
Within a few minutes, you should be able to connect to the API and run oc commands. This is faster due to the fact that the images exist in the alternate location.

In addition to forcibly powering nodes off, I also did some tests with cordoning, draining the nodes. There were no issues with nodes coming back up after performing these operations.
Next Steps
I am going to leave this isolated cluster online for a while just to see if there are any issues over time. This article will be updated if any issues occur.