
Backup and Restore of ETCD/Cluster State
These steps were tested with OCP version 4.6.
The documentation I am following is located at https://docs.openshift.com/container-platform/4.6/backup_and_restore/backing-up-etcd.html
In this article and associated videos, I will show 3 demonstrations. The first demonstration will show how to backup etcd data. Next, I will show you how to recover an etcd pod (this happens automatically by using the etcd cluster operator and forcing a redeployment). Lastly, a restore based on the backup taken in the first demonstration will restore the cluster to a previous state.
Here are some best practices related to etcd backups.
-You should wait approximately 24 hours before taking the first etcd backup due to certificate rotation.
-Backups only need to taken from one master. There is no need to run on every master.
-It is a good idea to store backups in either an offsite location or somewhere off the server.
-Run a backup before gracefully shutting down a cluster (IE: maintenance).
-Run a backup prior to upgrading a cluster in case there are issues.
Any commands that are to be run, will be italicized in this documentation.
Backup of ETCD State
In my environment, the master we will use to run the backup is called master1.ocp-poc-demo.com
1. oc debug node/master1.ocp-poc-demo.com
2. chroot /host
3. /usr/local/bin/cluster_backup.sh /home/core/assets/backup
Some ideas that could be implemented in the future would be to setup a cronjob to run this from time to time and copy this somewhere.
Recovering ETCD Pod
The following steps assume that the etcd pod is either missing or in some failed state (IE: crash loop). The cool thing about this process is that you don’t need an etcd backup since the other masters are in a good state.
In the video, the failing etcd member is master2.ocp-poc-demo.com
1. Let’s first get the status of the etcd pods.
oc describe etcd cluster|grep “members are available”
The output of this command will show how many etcd pods are running and also the pod that is failing. In this case, master2 is failing.
2. We will see how many etcd pods are running in the cluster.
oc get pods -n openshift-etcd|grep etcd|grep -v quorum

The output of this command will show the etcd pods running. Anything less than 3 is a problem.
3. Let’s change to the openshift-etcd project
oc project openshift-etcd
4. We will rsh into one of the etcd pods to run some etcdctl commands and to remove the failing member from the etcd cluster.
oc rsh etcd-master1.hub.ocp-poc-demo.com
etcdctl member list -w table

master2 still shows in the member list output. This doesn’t mean it is healthy. This just means that it is still a member.
If we look at the output of “etcdctl endpoint health -w table” or etcdctl endpoint status -w table“, you will either see the the endpoint missing (endpoint status) or the health state as false (endpoint health).

5. To get rid of the failing etcd member and force it to be recreated by the etcd operator, delete the id that corresponds to master2.hub.ocp-poc-demo.com.
These commands are still run from the etcd pod.
etcdctl member remove <id-of-master2>

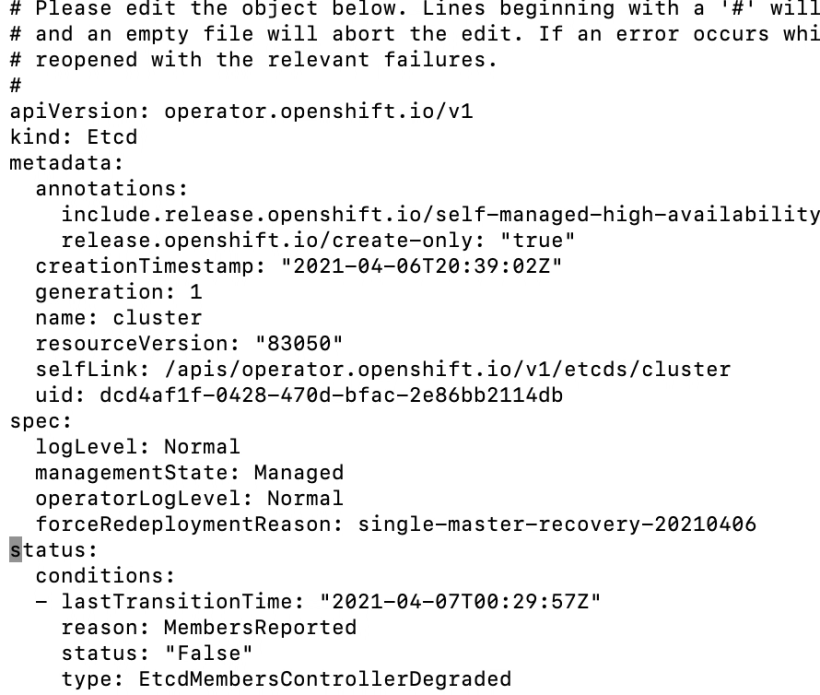
6. The last step is to force redeployment of the failed etcd pod by editing the etcd cluster object.
oc edit etcd cluster
in spec section, add “forceRedploymentReason: single-master-recovery-<date>”
7. The last step is to ensure that all of the etcd member pods are up (including master2.hub.ocp-poc-demo.com).
oc project openshift-etcd
oc get po

This should show all 3 pods up now
Lastly, you can rsh into any of the etcd pods and run etcdctl member list, etcdctl endpoint health, and/or etcdctl endpoint status. All of this output should show master2 is up and is a healthy member of the cluster.


Restore of Previous Cluster State
In this demonstration, I will create a new project called “thisprojectwilldisappear” to prove that a restore was made from a previous backup. This is the same backup that we did in the first part of this blog post.
The restore master server is master1.
- Create a project called “thisprojectwilldissapear”
oc new-project thisprojectwilldisappear
This is just used to prove that the backup is restoring to a previous point in time. - On master2 and master3, run the following commands:
oc debug node/<master2,3>
a. sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmp
This will force the etcd pod to stop
Check to see that etcd pod is stopped
sudo crictl ps a|grep etcd
Make sure no etcd pod is running
b. sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp
This will force kube-apiserver to stop
Check to see that kube-apiserver is stopped
sudo crictl ps a|grep kube-apiserver
c. Move all contents of etcd to /tmp
sudo mv /var/lib/etcd /tmp

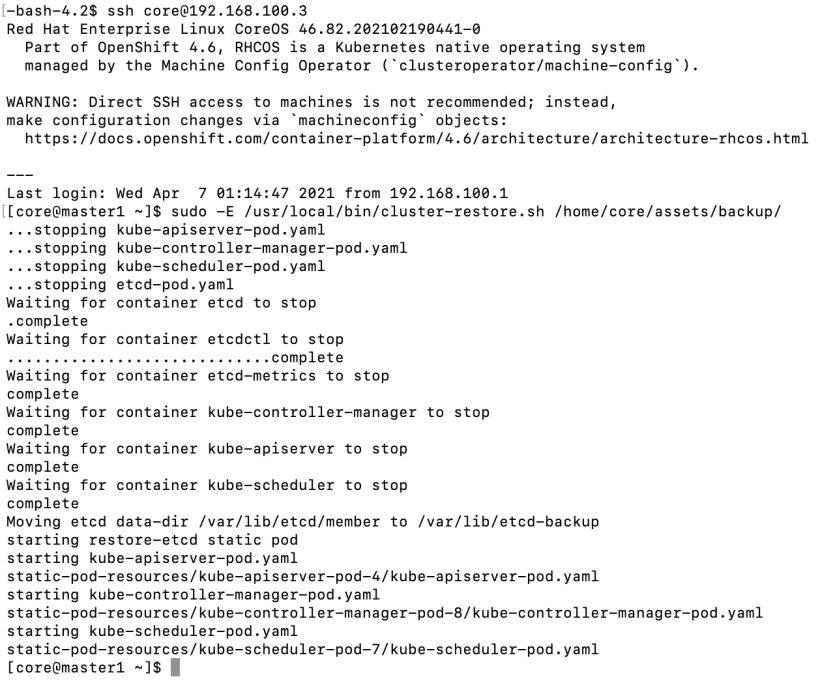
3. Since master1 is the only etcd member remaining, the restore will happen from here.
Either SSH to the master1 node or do “oc debug node/master1.hub.ocp-poc-demo.com”
Run “sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backup
4. Restart the kubelet on all masters.
systemctl restart kubelet (you may be asked to run systemctl daemon-reload as well)

5. Make sure all etcd pods are running. You may need to wait a few minutes
oc get po -n openshift-etcd|grep etcd|grep -v quorum
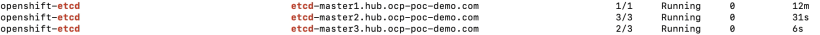
6. Edit the etcd cluster operator to force etcd redeployment.
oc edit etcd cluster
Edit the spec section to include forceRedeploymentReason: recovery-<date>

7. Either look at the etcd operator by running “oc get clusteroperators” to see the state as progressing or run “oc describe etcd cluster|grep NodeInstall

The status should show NodeInstallerProgressing
The clusteroperator status should show updating as true
8. Ensure that all etcd members come up and are all at same revision.
This is the bottom of the output of “oc describe etcd cluster“

In this screenshot, the latest version is 4. We need to wait until all etcd members are at this revision before proceeding.
If you notice any of the etcd pods don’t update, I found that deleting the pod and allowing it to recreate may fix this issue.
9. Edit the kubeapiserver cluster operator.
Edit the spec section to include forceRedeploymentReason: recovery-<date>
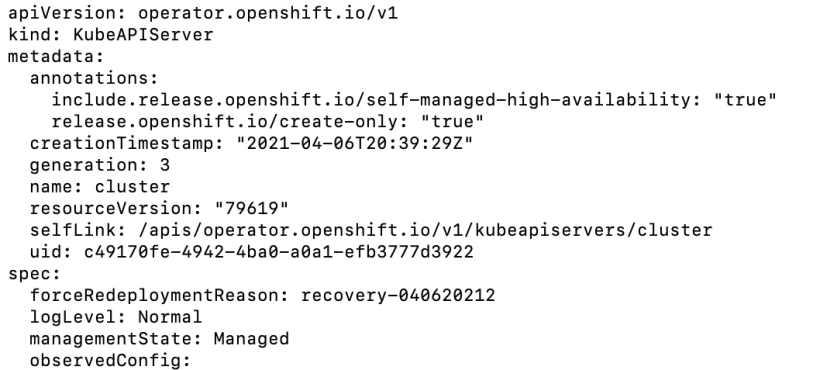
10. Either look at the kubeapiserver operator by running “oc get clusteroperators” to see the state as progressing or run “oc describe kubeapiserver cluster|grep NodeInstall“
The status should show NodeInstallerProgressing
The clusteroperator status should show updating as true

11. Ensure that all kubeapiserver members come up and are all at same revision. This is at the bottom of the output of “oc describe kubeapiserver cluster“

In this screenshot, the latest version is 5. We need to wait until all kubeapiserver members are at this revision before proceeding.
If you notice any of the kubeapiserver pods don’t update, I found that deleting the pod and allowing it to recreate may fix this issue.
12. Edit the kubecontrollermanager cluster operator.
Edit the spec section to include forceRedeploymentReason: recovery-<date>
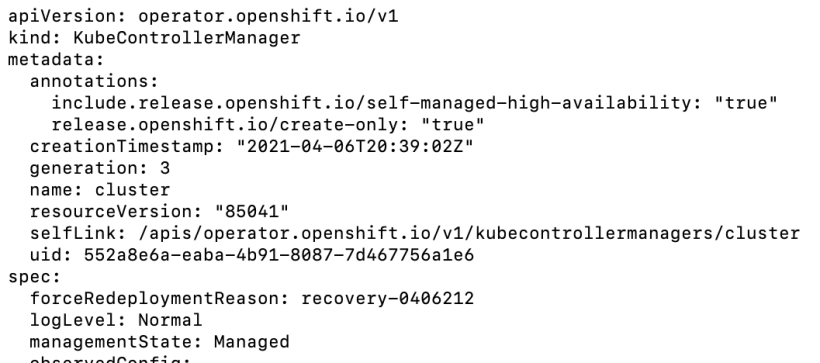
13. Either look at the kubcontrollermanager operator by running “oc get clusteroperators” to see the state as progressing or run “oc describe kubecontrollermanager cluster|grep NodeInstall“
The status should show NodeInstallerProgressing
The clusteroperator status should show updating as true
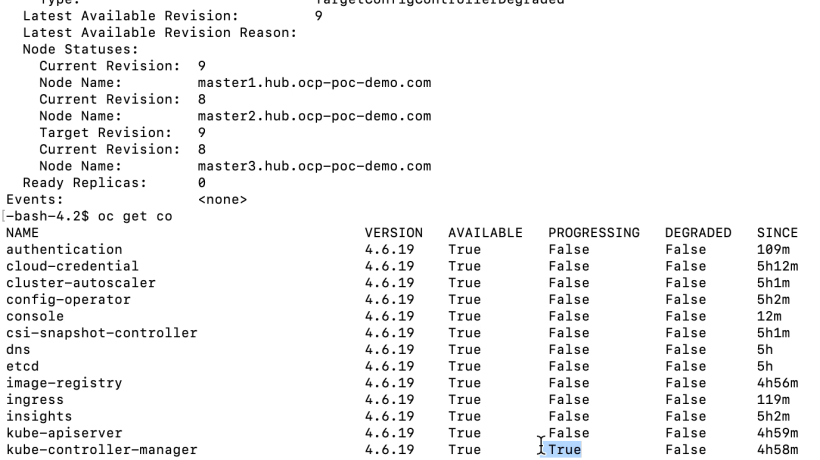
In this screenshot, the latest version is 9. We need to wait until all kubecontrollermanager members are at this revision before proceeding.
If you notice any of the kubecontrollermanager pods don’t update, I found that deleting the pod and allowing it to recreate may fix this issue.
14. Edit the kubescheduler cluster operator.
Edit the spec section to include forceRedeploymentReason: recovery-<date>
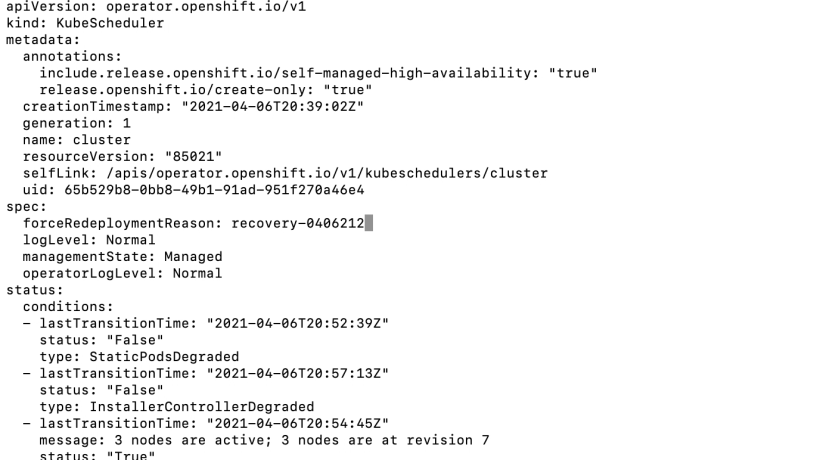
15. Either look at the kubscheduler operator by running “oc get clusteroperators” to see the state as progressing or run “oc describe kubescheduler cluster|grep NodeInstall“
The status should show NodeInstallerProgressing
The clusteroperator status should show updating as true


In this screenshot, the latest version is 8 We need to wait until all kubescheduler members are at this revision before proceeding.
If you notice any of the kubescheduler pods don’t update, I found that deleting the pod and allowing it to recreate may fix this issue.
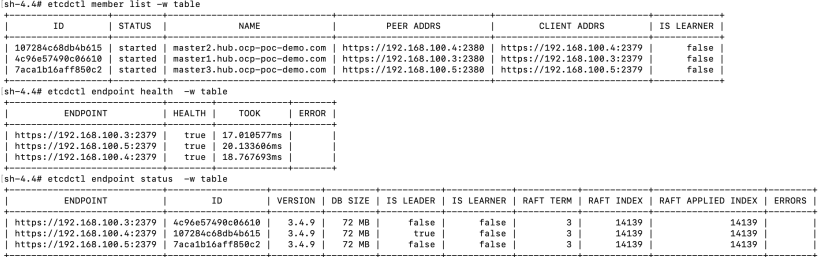
16. Re-verify that all etcd pods are up

And etcd cluster is healthy
17. Lastly, let’s check to see if that project we created earlier exists. The project is called “thisprojectwilldissapear”.
Try running the following command:
oc project thisprojectwilldisappear
It should no longer exist because it was created after the time the backup was taken.